1. The architecture gap between the Playbook and the Field Map
Two posts on this site frame the AI-in-telecom conversation from opposite ends. The Digital Transformation Playbook describes the organisational requirements: data sovereignty, agent orchestration, kill-switch design, governance, upskilling. The 2026 Field Map describes the use case landscape: which AI applications survive contact with production data, and which die in the sandbox.
There is a gap between them. The Playbook tells you what your organisation needs to look like. The Field Map tells you what to build. Neither tells you the architectural decisions that connect the two — the BSS-specific design commitments that determine whether your organisation’s AI ambitions are technically possible to execute.
That gap is where most operator AI programmes fail. The CTO has read the Playbook and built a steering committee. The CIO has read the Field Map and selected three use cases for the 2026 roadmap. The IT director has issued the RFP. And eighteen months later, the deployment is still in pilot, because the underlying BSS architecture cannot support the actions the AI is supposed to take.
The pattern is consistent across operators in MENA, GCC, and South Asia. The use cases that ship in production are the ones whose architectural requirements were either already met before the AI work began, or were addressed deliberately as part of the AI programme. The use cases that stall are the ones where the architectural debt was assumed away.
This post identifies the five BSS architecture decisions that determine which side of that line your operator ends up on. Each decision has a specific failure mode I have seen first-hand at scale across BSS environments. Each decision feeds at least one downstream area of the broader content series. None of them are optional — every operator makes a choice on each of these five, deliberately or by default, and the choice constrains everything that follows.
2. The five BSS architecture decisions
The five decisions, in the order they need to be made:
- The integration abstraction layer — how AI agents read from and write to BSS systems
- The product catalog as system of truth — whether the catalog is the canonical definition of the offer, or one of several competing definitions
- The order state machine and human-in-the-loop placement — where the human approval gate sits in the workflow
- The data plane and action plane separation — whether AI components that read data are architecturally distinct from components that act on systems
- The audit and rollback architecture — how every AI action is logged, attributed, and reversible
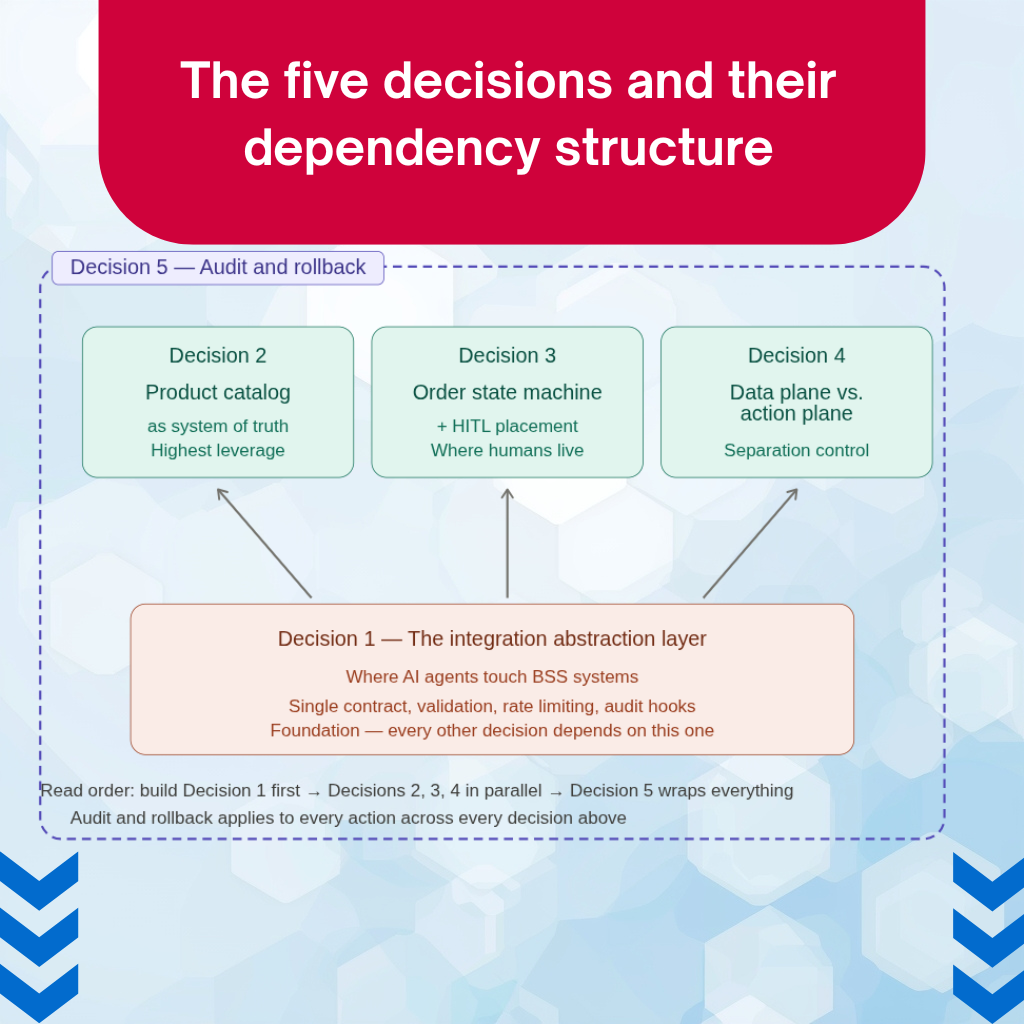
The order matters. Decision 1 enables 2, 3, and 4. Decision 5 wraps all of them. Operators who try to make decision 3 (the HITL gate) before decision 1 (the abstraction layer) end up with HITL gates that humans cannot meaningfully use — because the agent’s request is opaque and the human has no way to validate it. Operators who make decision 5 (audit) last find that retrofitting audit logging into a production agent system is significantly harder than building it in.
The rest of this post takes each decision in turn.
3. Decision 1: The integration abstraction layer
The first architecture decision is the most consequential and the most commonly skipped: where, exactly, do AI agents touch your BSS systems?
The default answer at most operators is “directly.” The agent calls the OCS API. The agent reads from the CRM database. The agent writes to the product catalog. This works in the pilot. It is the wrong architecture for production.
The right architecture is an integration abstraction layer between the agent and the BSS. The abstraction layer presents a stable, well-defined contract to the agent — a curated set of operations the agent is permitted to perform, with input validation, output normalisation, rate limiting, and audit hooks built in. The agent does not know whether the underlying system is Amdocs CES, Ericsson OCS, Netcracker, or a custom in-house build. It knows only the abstraction layer’s contract.
Three things break without this layer. First, every BSS upgrade, vendor swap, or schema change requires re-engineering the agent. The abstraction is the buffer that lets BSS evolve independently of AI logic. Second, the agent’s blast radius is uncontrolled — a misbehaving agent can call any API the credentials permit, including ones the agent should never touch. The abstraction layer is where you enforce least privilege at the action level, not just the credential level. Third, audit becomes scattered across vendor logs in different formats, in different retention windows, with different field names. Centralised audit lives at the abstraction layer.
This decision is also where the security argument from the Glasswing post generalises. The custom integration code that an attacker with a fine-tuned local model is most likely to find vulnerable is precisely the integration code that does not live in a vendor product. An abstraction layer is also a security control surface — a single place where input validation, schema enforcement, and anomalous request detection can be applied across every agent action.
The next post in this series goes deep on what the abstraction layer looks like in practice — see Why AI Agents Die at the BSS Boundary when published. For now, the architecture decision is binary: agents talk to BSS through an abstraction, or they don’t. Operators who say “we’ll add the abstraction later” almost never do, because by the time they want to, three agents have hard-coded direct API calls and the cost of refactoring exceeds the original build.
4. Decision 2: The product catalog as system of truth
The product catalog is the most-leveraged architectural artefact in any BSS environment. Every charge, every entitlement, every promotion, every customer-facing offer description traces back to it. It is also, at most operators, the most fragmented. The version in the CRM does not match the version in the billing system. The version in the self-care portal lags both by six weeks. The version in the agent’s training data is older still.
The architecture decision is whether the catalog is the system of truth — meaning every other system reads from it, downstream — or whether it is one of several competing definitions, with reconciliation logic in between.
The “competing definitions” pattern is what most mature operators actually run, and it is incompatible with most useful agentic AI. An agent that needs to answer “is this customer eligible for the family plan upgrade” needs to know what the family plan currently offers, who is eligible, what the price is in this market, and whether the offer is currently active. If the agent reads from the CRM, it gets the marketing description. If the agent reads from billing, it gets the rating rules. If the agent reads from the catalog directly, it gets both — but only if the catalog is actually the source. Otherwise the agent gives a confident, fluent, wrong answer.
The decision splits operators into two groups. Group one: catalog is the system of truth, downstream systems publish-subscribe to catalog changes, agents read from a normalised catalog API. Group two: catalog is one input among several, reconciliation runs nightly, agents read from whichever system happens to be most recent. Group one ships AI use cases. Group two cannot.
This is the highest-impact decision in the five, because it determines which use cases are even possible. The “generative interactive bill” use case in the Field Map only works if the catalog is authoritative — otherwise the AI explains charges using yesterday’s rate definitions. The “AI-assisted enterprise provisioning” use case only works if catalog changes propagate predictably. Continuous revenue assurance only works if the rating rules the AI is validating against are the same rating rules the OCS is using.
The remediation is significant. Most operators with the “competing definitions” architecture need a multi-quarter programme to consolidate. The remediation cost is real. The cost of not remediating is that the operator’s AI roadmap is permanently constrained to the use cases that don’t depend on catalog correctness — which is roughly half of the Field Map’s high-impact tier.
5. Decision 3: The order state machine and human-in-the-loop placement
Every BSS environment has an order state machine. Some are explicit, in a dedicated order management system. Some are implicit, scattered across CRM, billing, and provisioning systems with state inferred from the combination. The architecture decision is whether the state machine is explicit and visible to agents, and where in that state machine the human approval gate is placed.
The default failure mode is the implicit state machine. Order state lives in three systems. The agent has to infer state by querying each one and combining the answers, which it does inconsistently because the systems disagree about edge cases. The HITL gate, when it exists, is placed at the wrong point — usually too late, after the agent has already triggered downstream effects that are expensive to roll back.
The right architecture has three properties. The order state machine is explicit, owned by a single system, and exposed through the integration abstraction layer. Every state transition the agent can request is enumerated, and each transition has a defined risk tier. The HITL gate sits at the highest-risk transition the agent reaches in any given workflow, not at the start and not at the end. And the human at the gate sees the agent’s full reasoning chain — not just the final decision — so the approval is meaningful rather than rubber-stamping.
The same principle drove the closed-loop recovery design in the revenue assurance post. The HITL gate in that workflow sits at the corrective action approval step, not earlier and not later. Below threshold, auto-approve; above threshold, queue for analyst review with full context. The threshold itself is owned by the CFO’s office, not the IT team, because it is a risk governance decision rather than a technical parameter.
Order fallout is the natural worked example. An operator with a clean order state machine and well-placed HITL gates can run an agent that handles 80% of fallouts autonomously and routes the remaining 20% to humans with full diagnostic context. An operator with implicit state and misplaced gates cannot run that agent at all — every fallout requires human review, which means the agent has not actually reduced workload. This is the gap between the Field Map’s “demo works, production doesn’t” pattern and an operator who has done the architectural work.
6. Decision 4: The data plane and action plane separation
This decision is the most under-discussed in vendor pitches and the most consequential for operational risk. Every AI component in a BSS environment has two possible modes: it can read data, and it can act on systems. The architecture question is whether these two modes are separated.
In most operator deployments, they are not. The agent that reads customer data is the same agent that issues credits. The agent that monitors billing events is the same agent that adjusts rating rules. The pattern is convenient because it minimises infrastructure, and it is dangerous because it eliminates a critical control boundary.
The right architecture separates the data plane from the action plane. Components in the data plane have read access to whatever they need. Components in the action plane have narrow, audited write access to specific systems and specific operations. The two communicate through structured proposals — the data plane component identifies a situation that warrants action, formulates a proposed action with full context, and hands it to the action plane component, which evaluates it against policy and either executes or escalates.
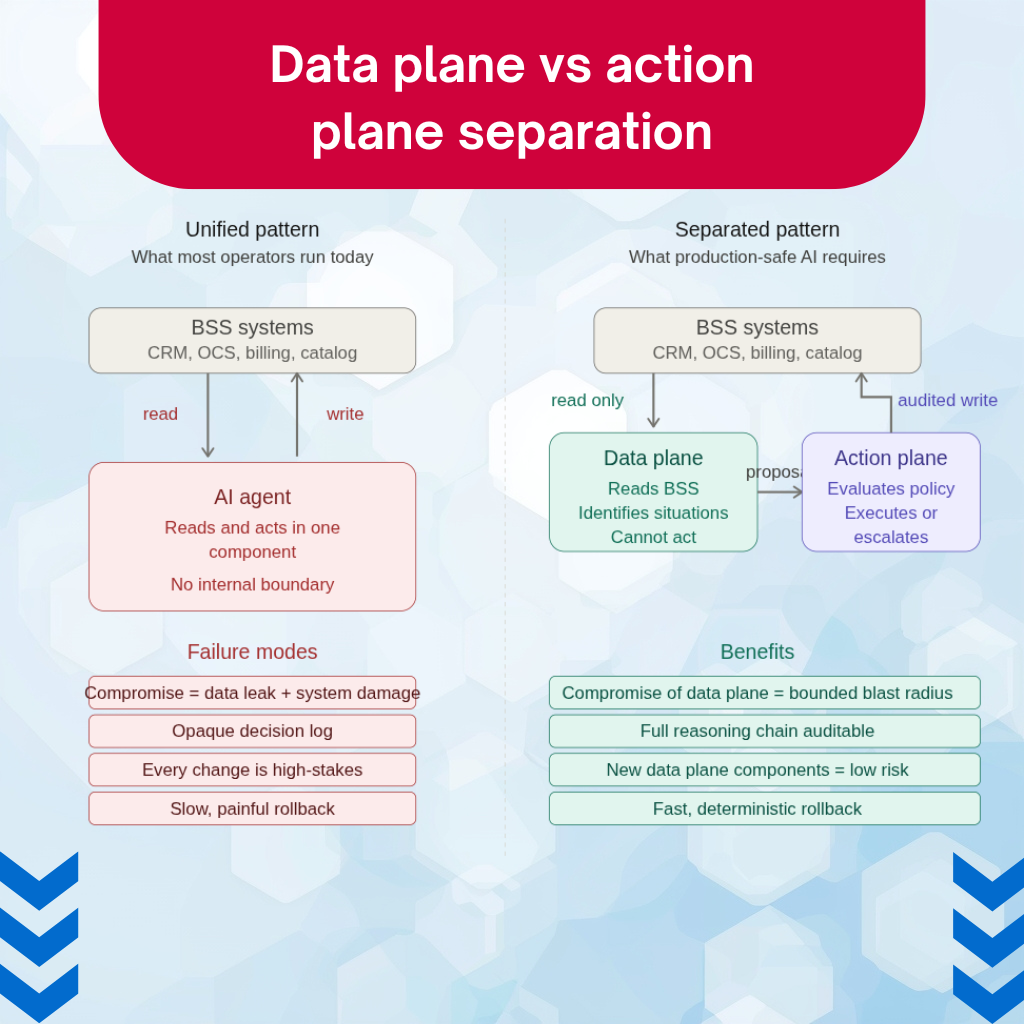
Three reasons this matters more than it sounds. First, security: a compromised data plane component is bad but bounded — it can leak data, it cannot wreck operational state. A compromised unified component can do both. The Glasswing analysis applies most sharply to the unified pattern, because every data-plane vulnerability is also an action-plane vulnerability. Second, observability: separated planes produce a clear log of “agent observed X → agent proposed Y → action plane evaluated Y → result Z,” which is auditable. Unified components produce a single opaque decision that is much harder to validate after the fact. Third, recovery: when an action goes wrong, knowing which proposal led to it and why the action plane approved it is the difference between a five-minute rollback and a four-hour incident.
This is also the decision that determines whether the operator can adopt new AI capabilities incrementally. Adding a new data-plane component is low risk — it observes more, it acts on nothing. Adding a new action-plane capability is a deliberate, scoped operation. Operators with unified architectures cannot make this distinction; every AI addition is high-stakes by default.
7. Decision 5: The audit and rollback architecture
The fifth decision is the one most often deferred and most painful to retrofit. Every AI action in the BSS environment must be logged, attributed, and reversible. This is non-negotiable for three reasons: regulatory compliance, internal accountability, and operational recovery.
For operators in MENA — under NDMO oversight in KSA, TDRA in UAE, PTA in Pakistan — the audit trail is increasingly being treated as a regulatory artefact, not just an operational record. Each of these regulators is moving in the direction of explainability requirements for AI-driven decisions in regulated industries. Telecom is squarely in scope. Operators who design audit logging to a regulatory-grade standard from day one have a much shorter compliance gap when the requirements crystallise.
The architecture has four properties. Every AI action is logged with a unique correlation ID that traces back through the data plane decision and the action plane approval. The log records the model version, the prompt or input context, the proposed action, the policy evaluation, the human approval (if applicable), and the execution result. Logs are tamper-evident — write-once or cryptographically signed — and retained per the longer of regulatory requirement or three years. And every action category has a defined rollback path, pre-tested, with a documented owner.
The rollback architecture is the part most operators get wrong. They log everything but they never test rollback. When an action goes wrong in production, the team improvises a recovery, and it works or it doesn’t. The disciplined version is to define the rollback procedure for each action category at the same time as the action itself, and to test the rollback in a staging environment as part of every release. This is borrowed practice from financial services back-office systems and is increasingly standard there. Telecom BSS is twenty years behind on this and catching up is overdue.
8. The maturity ladder these decisions define
The five decisions, taken together, define a maturity model with five stages:

Stage 1 — Implicit and direct. No abstraction layer. Catalog fragmented. Order state implicit. Data and action planes unified. No structured audit. AI deployments are pilots that don’t reach production. This is where most operators sit.
Stage 2 — Abstracted but unified. Integration abstraction layer in place. Catalog still fragmented. Order state still implicit. Data and action planes unified. Audit partial. Some AI use cases ship — typically advisory ones from the Field Map’s high-implementation-reality tier.
Stage 3 — Catalog-correct. All Stage 2 properties plus the catalog as system of truth. Order state still implicit but agents can at least reason about offers and entitlements correctly. Continuous revenue assurance and bill explainer use cases become viable.
Stage 4 — State-machine clean. All Stage 3 properties plus explicit order state and well-placed HITL gates. Order fallout automation and AI-assisted provisioning become viable. This is where the Field Map’s medium-implementation-reality tier starts shipping.
Stage 5 — Plane-separated and audit-complete. All previous properties plus data/action plane separation and full audit/rollback architecture. New AI capabilities can be added incrementally without elevated risk. This is the architectural state where agentic AI in BSS is actually safe to scale, and the regulatory posture is sustainable.
Most MENA and South Asia operators are between Stage 1 and Stage 2 today. The serious vendors and SIs in the region are quietly aware of this and price the transformation work accordingly. The honest framing for an operator’s board is not “where do we want to be on the AI maturity curve” but “where are we on this architecture maturity ladder, and what is the cost of advancing one stage.”
9. What this means for your next 18 months
The sequencing argument is straightforward. Decision 1 (integration abstraction) is the foundation; nothing else works without it, and it is the cheapest of the five to get right early. Decision 2 (catalog) is the highest-leverage and the most expensive — it should be a separate programme, not bundled with AI work. Decisions 3 (state machine and HITL), 4 (plane separation), and 5 (audit) should be designed in parallel as part of any AI deployment, not added afterwards.
Operators who try to ship AI use cases without making these decisions deliberately will discover, eighteen months in, that the use cases that worked in the sandbox are the use cases whose architectural requirements were small enough to brute-force. The use cases that justify the AI investment — order fallout, continuous revenue assurance, agentic provisioning — require the architectural work, and there is no shortcut.
The Playbook tells you what an AI-ready organisation looks like. The Field Map tells you which use cases work. This post is the layer in between. Make these five decisions deliberately, in the right order, and the organisation the Playbook describes can actually execute the use cases the Field Map identifies. Make them by default, and the gap between pilot and production stays exactly where it is.