1. Introduction
It was a Tuesday at 2am, which meant roaming settlement runs had just kicked off in the background while everyone who understood the configuration was asleep.
By the time anyone noticed, the mismatch had been compounding for eleven months. Eight figures. One interconnect partner. A rating rule that looked correct in the product catalog, fed an incorrect discount tier downstream in OCS, and reconciled against the wrong rate table in mediation. Every system did exactly what it was told. No alarms fired. The RA team found it during a quarterly spot check, not because any automated system flagged it.
That story is not unusual. Variations of it run at operators across MENA and South Asia every quarter. The leakage isn’t hidden — it’s buried in process gaps between systems that don’t share a common truth about what a transaction is supposed to cost.
KPMG’s Global Revenue Assurance Survey puts industry leakage at 1–10% of revenue, with developing market operators in the upper half of that range. The estimate that circulates inside most RA teams is around 7%. That number has barely moved in fifteen years.
The tools got better. Detection accuracy improved. Machine learning found anomalies that rule-based engines missed. And yet the number didn’t move — because the problem was never purely detection. It was always the gap between finding the leak and closing it.
That’s what agentic AI changes. Not the detection layer. The recovery loop.
Detection has been solved for a decade. Recovery is still broken. Here’s where AI actually changes the math.
2. Where leakage actually happens: five signatures
Most vendor-led RA conversations start with the anomaly detection demo — a dashboard lighting up with exceptions. What they skip is the taxonomy of why exceptions exist in the first place. Here are the five patterns that account for the majority of recoverable leakage in a modern BSS stack.
Mediation gaps between CDR and charging. The CDR leaves the network element correctly formatted. Mediation parses it, transforms it, and forwards it to OCS or the billing engine. The problem lives in the transform logic — timezone normalization errors, duplicate suppression that drops legitimate records, and format conversion failures that send a zero-value record rather than rejecting cleanly. These don’t produce alarms. They produce silent revenue holes that reconciliation catches weeks later, if at all.
Rating errors from product catalog misconfiguration. Product catalogs in mature operators are archaeological sites. Fifteen years of promotions, M&A migrations, and regulatory mandates layered on top of each other. A rating rule that correctly prices Plan A does something unexpected when a subscriber is mid-migration between Plan A and Plan B and has a grandfathered discount that was created in a billing system that no longer exists. The OCS rates it. The revenue is posted. And the amount is wrong. Often by a small percentage — small enough that individual records don’t trigger thresholds, large enough that at volume it matters.
Interconnect reconciliation failures. Your CDRs say X minutes at Y rate with Partner Z. Partner Z’s CDRs say something different. The settlement window is 30 days. The dispute resolution SLA is 60 days. In that gap, revenue sits in suspense or gets written off. Roaming is the worst case — multiple intermediate carriers, each with their own CDR format, each with settlement windows that don’t align. This is the category where the 11-month mismatch happens.
Discount and promotion misapplication. A promotion expires on the 15th. The billing run closes on the 30th. The promotion discount continues to apply because the deactivation event didn’t write cleanly to the product catalog, which didn’t propagate in time to the rating engine, which applied the last known rate. This is a known failure mode in operators running separate product catalog and CRM systems with async integration between them. It costs more than most IT teams realize because it’s diffuse — many accounts, small amounts each.
Roaming settlement disputes. Already touched above, but worth separating from general interconnect. IOT rate tables expire. Bilateral agreements get renegotiated. The rate the hub carrier charges doesn’t match the rate the visited network agreed to. Operators running manual settlement workflows in spreadsheets against partners with automated dispute engines are systematically losing these negotiations — not because they’re wrong, but because they’re slow.
3. What detection AI has already done
The ML-based RA platforms — Subex, TELARIX, WeDo (now Xintec), and the custom implementations operators have built — genuinely solved the detection problem. Pattern recognition across CDR streams, threshold-based anomaly scoring, cross-system correlation that rule engines couldn’t manage. These tools can flag mediation gaps within hours now, not weeks.
The result is that most mature operators have good anomaly detection. What they have is a daily exceptions queue. Sometimes hundreds of items. Each item requires a human analyst to classify it, determine the corrective action, get approval, and then manually trigger whatever downstream process fixes the underlying record.
The bottleneck moved. Detection is no longer the constraint. Human analyst bandwidth is the constraint. And that’s a fundamentally different problem to solve.
4. The closed-loop problem
Here’s the pattern that RA managers across the region describe in almost identical terms: the leak is found on day 30. The correction ticket is raised on day 32. It sits in the backlog until day 45. The analyst who owns it is on another project. It escalates to a manager on day 50. The billing team schedules the correction for day 60. The customer — if it’s an overcharge rather than an undercharge — already called care on day 38, got nowhere, and ported out on day 45.
Detection without recovery doesn’t recover revenue. It produces a ledger of losses with timestamps.
The closed-loop problem has three components that AI doesn’t solve automatically just by being present:
Validation before action. Not every anomaly is a genuine leak. Some are measurement artifacts. Some are legitimate edge-case billing scenarios that look wrong but are correct. An agent that triggers corrective action on every exception will create more problems than it solves. The validation layer — classifying whether an anomaly is actionable — requires enough context about the product catalog, the customer segment, and the transaction history to make a reliable judgment. This is where LLM-based classification adds genuine value over rule-based approaches, because it can reason about combinations it hasn’t explicitly seen before.
Action determination. For a confirmed leak, the corrective action isn’t always obvious. A mediation gap that dropped 500 records might require a replay from raw CDRs — if the raw CDRs are still in retention. A rating error might require a credit to the customer and an adjustment to the next billing run. A roaming dispute might require generating a counter-claim document against the partner’s settlement. Each action type maps to a different downstream system and a different process owner. The agent needs to know which action to trigger and how to trigger it, which means it needs a reliable model of the BSS stack’s corrective action surface.
Human approval thresholds. This is the design decision that determines whether an agentic RA system stays in production or gets shut down after the first large-scale mistake. Some corrective actions can execute autonomously below a threshold — a $50 credit to a postpaid account is low risk. A $5,000 billing adjustment to a corporate account requires human sign-off. A dispute claim against an interconnect partner requires legal review. The threshold design isn’t just a technical parameter. It’s a risk governance decision that the CFO’s office owns, not the IT team.
Until all three of these are addressed, “agentic RA” is just detection with a fancier dashboard.
5. Architecture walkthrough
The architecture that addresses this doesn’t require replacing your RA platform. It adds a recovery orchestration layer on top of it.
The workflow runs as a state machine with six nodes:
Detection → existing RA platform outputs an exception. This part stays as-is.
Validation → an LLM-based classifier receives the exception with full context: the CDR, the product catalog state at transaction time, the customer segment, and the recent transaction history. It outputs a validation decision with a confidence score and a reasoning trace. Below a confidence threshold, it routes to human review rather than continuing.
Corrective action determination → for validated exceptions, the agent maps the exception type to the appropriate corrective action from a pre-defined action catalog. The action catalog is the critical configuration artifact — it defines what the agent is allowed to do, to which systems, under what conditions.
Human approval gate → the agent evaluates the corrective action against the threshold configuration. Below threshold: auto-approve and continue. Above threshold: pause, generate a human-readable summary of the exception and proposed action, and queue for analyst approval. This is where LangGraph’s state persistence matters — the workflow stays paused with full context intact until the human acts.
Execution → approved actions are executed via API calls to the relevant system: billing engine, product catalog, care platform, or interconnect settlement module. n8n handles the actual API orchestration here — it’s reliable, auditable, and integrates with virtually every BSS API surface without custom code.
Audit logging → every decision in the chain is logged: the exception, the validation reasoning, the action determination, the approval decision, the execution result, and any exceptions. This is non-negotiable for regulatory environments. The log is the evidence trail if an RA correction is ever disputed.
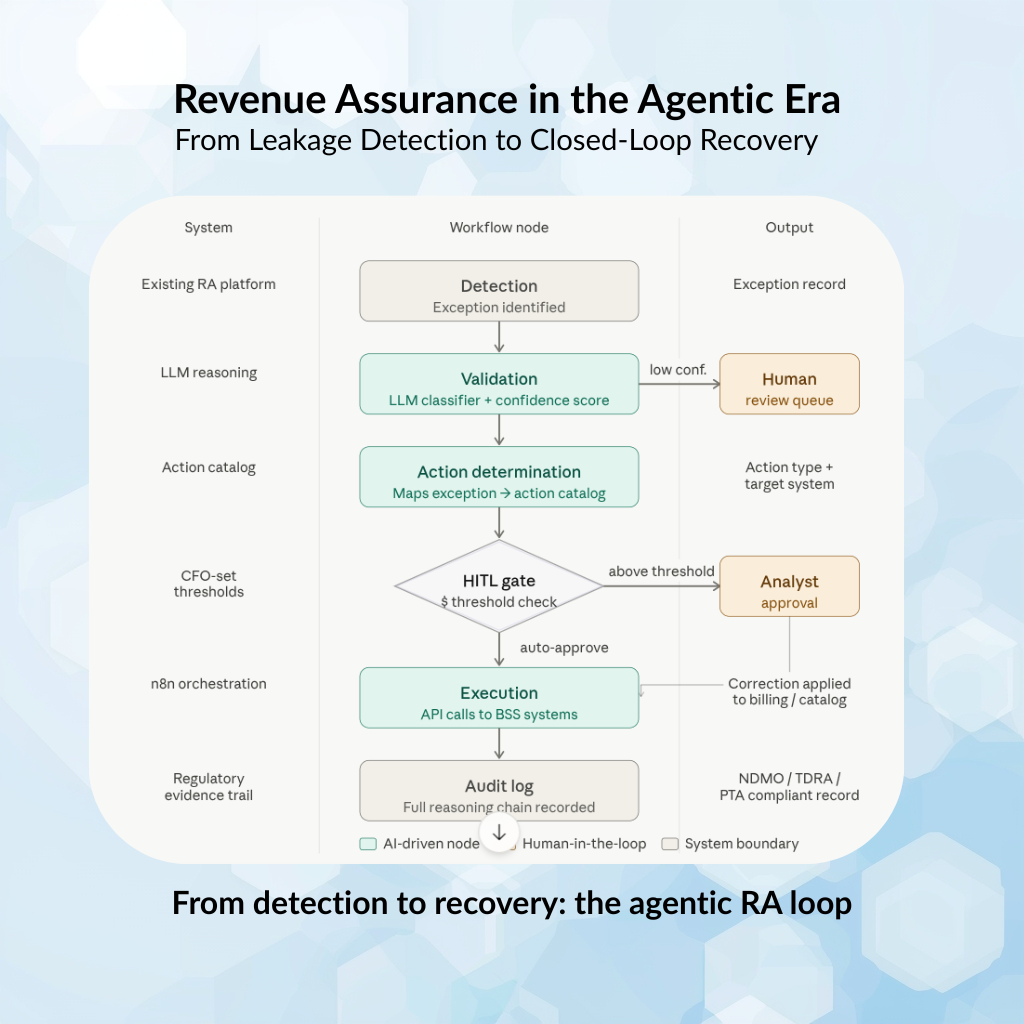
Full technical depth on the LangGraph state machine design lives in a separate post. The point here is the architecture shape: detection is not the loop. Recovery is the loop. And the loop requires a human in it, in the right place.
6. The MENA math
Theory is fine. Here’s what it looks like at operator scale.
Take a mid-size GCC or South Asia operator: 10 million subscribers, ARPU of $7/month (conservative — lower than MENA average, which makes the case harder and therefore more credible). Annual revenue: approximately $840 million.
At 3% leakage, that’s $25 million per year leaving through gaps the RA team knows exist but can’t recover fast enough. At the industry-typical 7%, it’s $59 million.
Now the agentic question: if closed-loop recovery doubles the current recovery rate — not eliminates leakage, just recovers it faster and more completely — what’s the value? At 3% leakage with current partial recovery, recovering an additional 1 percentage point of revenue = $8.4 million per year. That’s not a cost optimization number. That’s a revenue line.
Deloitte’s 2026 Telecom Outlook is direct on this: ARPU across MENA is largely stagnant, with only a minority of operators reporting growth. In that environment, every dollar recovered from leakage is a dollar that doesn’t require a new subscriber, a new product launch, or a new market to acquire.
The question for the CFO’s office isn’t whether to invest in agentic RA. It’s whether the current RA team’s human bandwidth can extract more than 1% of revenue back in a year without it. For most operators, the honest answer is no.
7. What this means for your RA architecture
If you’re running a mature RA platform and your detection metrics look good, the audit question isn’t “are we finding the leakage?” It’s “what’s our mean time from detection to closed correction, and what percentage of exceptions ever get corrected at all?”
Most RA teams can answer the first question easily. Many can’t answer the second.
Before building or procuring an agentic recovery layer, three architecture decisions need to be locked:
Action catalog scope. Define explicitly what the agent is allowed to do. This is a governance document before it’s a technical specification. Every action type needs a system owner, an approval tier, and a rollback path.
Threshold design. The dollar thresholds that determine autonomous action vs. human approval should be set by the CFO’s office and the risk function, not by the vendor and not by the IT team alone. They should also be reviewed quarterly, not set once at implementation.
Audit logging standard. For MENA operators under NDMO (KSA), TDRA (UAE), or PTA (Pakistan) oversight, the audit trail is a regulatory artifact, not just an operational record. Design it to that standard from day one. Retrofitting audit logging into a production agent system is significantly harder than building it in.
The operators who will extract value from agentic RA in the next 18 months are not the ones who buy the best detection platform. They’re the ones who fix the recovery loop.
Shoaib HB is an independent BSS/CRM consultant with 18 years at Mobilink (now Jazz) and Zain KSA. He advises telecom operators and system integrators across GCC, South Asia, and MENA on BSS integration, revenue assurance, and AI deployment risk. shoaibhb.com